
OpenAI o3 and the Rise of the Intelligence Allocator
The implications of rapidly increasing inference costs


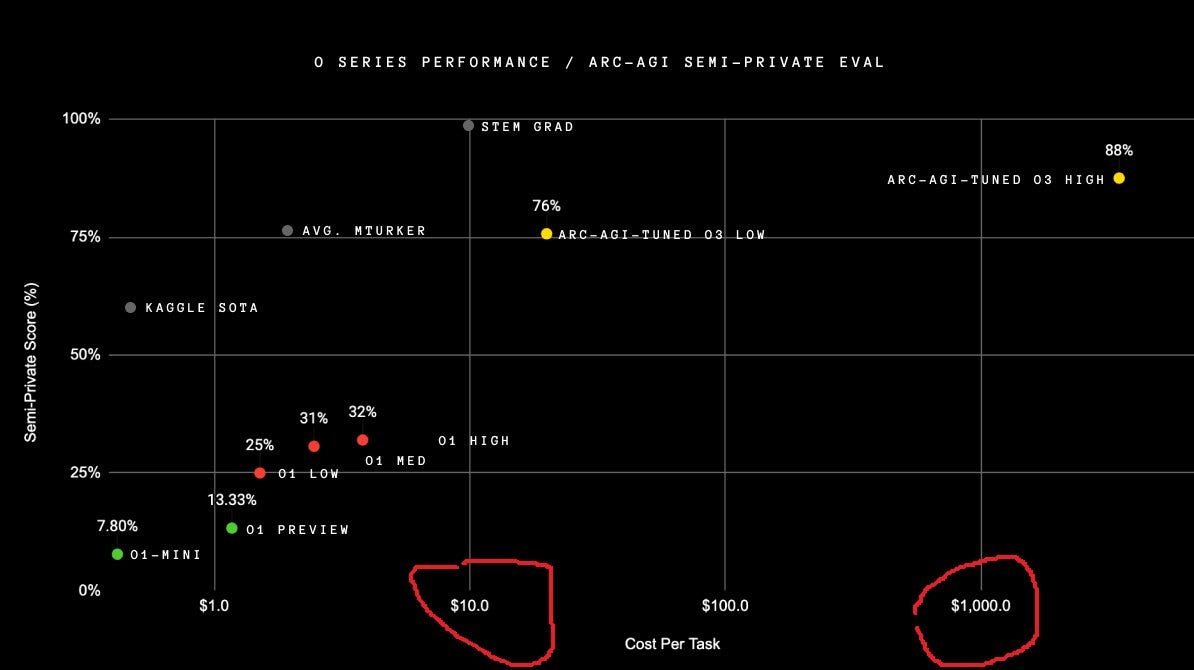
OpenAI's announcement of their o3 series of models represents a pivotal moment in AI development - but not for the reasons many might expect. While the headline achievement of 87% on ARC AGI is impressive, the more transformative aspect lies in the economics of the model's deployment.
Let's start with the raw numbers: A single inference task on o3 at its highest compute setting costs over $1,000 (see the figure below). This isn't $1,000 per evaluation set or per session - this is per individual task. To put this in perspective, that's roughly equivalent to 5-10 hours of skilled human labor cost, dedicated to solving a single problem. The model offers lower compute settings, but with corresponding decreases in capability. This creates a direct tradeoff between cost and intelligence that we haven't had to grapple with before.
This cost structure represents a sharp departure from the trend we've observed over the past two years. During that period, the cost of running general-purpose language models has approached zero, even as their capabilities have steadily improved. GPT-3.5 became GPT-4, yet inference costs remained relatively stable. GPT-4 then became GPT-4 Turbo and GPT-4o, maintaining intelligence while rapidly decreasing inference costs. This led to a proliferation of AI applications - we could afford to experiment freely, integrating AI into virtually every workflow to see what stuck.
The o3 series shatters this paradigm. When each inference costs more than a decent laptop, you can't simply "throw AI at the problem" anymore. Every use of high-compute o3 needs to be justified by the value it creates. This introduces what we might call the "inference allocation problem" - how do we determine which tasks are worth deploying our most powerful (and expensive) models on?
Consider a software development team using o3 for code analysis. Running the model at high compute to analyze a critical security vulnerability in a payment system might be easily justifiable. But what about using it to optimize a non-critical internal tool? Or to review routine pull requests? The team now needs to develop frameworks for making these decisions systematically.
This fundamentally transforms AI deployment into a capital allocation problem. Just as investment managers spread limited capital across opportunities to maximize returns, organizations must now optimize their allocation of inference compute to maximize value creation.
Consider a hypothetical AI budget of $1 million per month. Currently, this might support tens or hundreds of millions of GPT-4o inferences spread across hundreds of different use cases. With o3, the same budget only covers about 1,000 high-compute inferences. This scarcity forces us to think like capital allocators: Which thousand problems, if solved with our highest level of artificial intelligence, will generate the most value?
Beyond simply identifying high-value problems, intelligence allocators will need to understand the relationship between compute investment and value creation. Sometimes, a medium-compute inference at $100 might capture 80% of the potential value at 1/10th the cost. In other cases, the step-change in capability from high-compute might be worth the premium. Like any good investment decision, it requires understanding both the cost of capital and the expected returns.
In another parallel to traditional capital allocation, just as investors develop frameworks for evaluating investments across different sectors and risk levels, organizations will need frameworks for evaluating AI compute allocation across different use cases. These frameworks will need to consider factors like:
The value delta between using high-compute versus lower-compute models
The cost of being wrong or suboptimal
The potential for value capture from improved accuracy
The frequency with which the task needs to be performed
We might even see the emergence of "AI portfolio theory" - methods for optimizing the allocation of compute resources across different types of tasks to maximize expected return while managing risk. Some organizations might adopt a "barbell strategy" - using basic models for routine tasks while reserving expensive high-compute inferences for their most critical problems.
This shift in focus for AI engineers means that success looks more like developing the frameworks and metrics needed to make intelligence allocation decisions effectively, rather than focusing purely on technical implementations. The best AI engineers will be those who can think like capital allocators, understanding both the technical capabilities and the business value of different compute investments.
In this light, o3 represents the beginning of an era where artificial intelligence must be treated as a scarce resource requiring careful allocation. The organizations that thrive will be those that develop robust frameworks for deploying this resource where it can generate the highest returns.
The future of AI might look less like unlimited abundance and more like traditional capital markets, where success comes from making smart allocation decisions with limited resources. As models continue to become more powerful and computationally intensive, these allocation skills will only become more crucial.