
The Strategic Implications of GPT-5 for OpenAI
OpenAI shifts away from the enterprise and toward the consumer

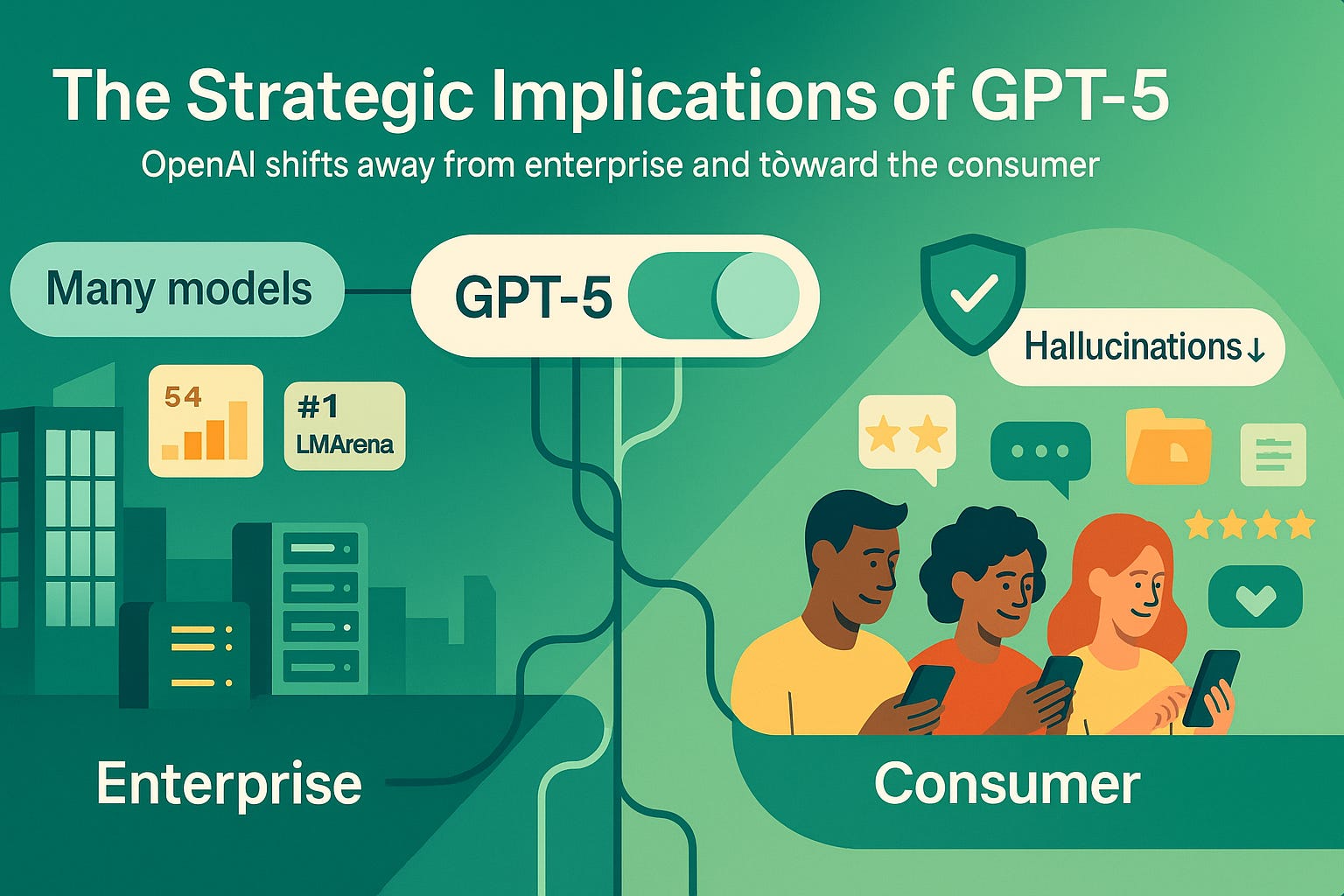
After years of anticipation and hype, GPT-5 is finally out. And the results are decidedly mixed. GPT-5 is undoubtedly a great model — it is #1 across the board on LMArena, sets new highs in SWE-Bench and a host of other coding tasks, and performs great across a range of math benchmarks. However, the expectations for GPT-5 were that it would blow the competition out of the water. Instead, it has made incremental improvements across all of these benchmarks, and is highly likely to be passed over whenever Google releases its next Gemini model in short order (or just when Gemini 2.5 Deep Think gets benchmarked!)

The largest gains to GPT-5 came in a less performance-based metric: it seems that, for this release, OpenAI highly prioritized reducing hallucinations and sycophancy in model output.

So you may not notice large performance differences between GPT-5 and the leading models from other labs (or even when compared to OpenAI’s o3 model), but you likely will notice that the model is much less likely to make things up and say things that are flat out wrong just to produce an answer.
In addition, you will likely notice in the ChatGPT model picker that all of the previous models are gone: now there’s only GPT-5. This is another one of GPT-5’s main contributions — it greatly simplifies the model selection process. GPT-5 is more of a system than a model, dynamically routing requests to faster LLMs (analogous to GPT 4o) or slower, thinking LLMs (analogous to o3) depending on the complexity of the request.
(The two above points are important; we’ll come back to those later).
Likely in response to some widespread dismay at the performance benchmarks, Sam Altman tweeted the following after the GPT-5 announcement:

“we can release much, much smarter models”
It seems Altman is asserting that OpenAI deliberately chose to release a model below the company’s capabilities, barely edging out its competitors (and likely not even edging out Google’s leading model) on most performance metrics. Instead, they deliberately chose to focus on reducing hallucinations and streamlining model selection as the main contributions of GPT-5. Why would OpenAI do this? Why not continue setting the benchmark for LLM model performance, as they’ve done since the ye olde days of GPT-2?
Because the strategic focus of the company has clearly shifted.
Market Dynamics Affecting OpenAI
ChatGPT is a consumer application with 700 million weekly active users. And it is absolutely trouncing the competition in consumer adoption. The ChatGPT app in the Apple App Store has 3.3 million reviews, compared to just 377,000 for the Gemini app and 23,000 for the Claude app. This suggests that ChatGPT has a mobile install base that is 10x the size of Google Gemini and 100x the size of Anthropic’s Claude. Moreover, in June 2025, openai.com had 1.12 billion visits, while gemini.google.com had 265 million and Claude had 113 million — again suggesting a lead of at least an order of magnitude for OpenAI over its competitors in the consumer chat space (source: https://www.semrush.com/).
By contrast, according to a Menlo Ventures report from July 2025, Anthropic is actually the leading market provider for enterprise LLM API usage, with 32% market share vs. OpenAI’s 25% market share in mid-2025. Google is also growing and not far behind OpenAI, at 20% market share, up from 12% in 2024. OpenAI’s enterprise position has also been trending strongly negative, cratering from 50% market share in 2023 down to its current position of 25% market share in mid-2025.

So we see the market dynamics pressing on OpenAI as a company — absolutely dominant positioning on the consumer side of the market, with a weak (and steadily weakening) position on the enterprise side of the market. This leaves OpenAI with a choice — double down on its success on the consumer side of the market, or attempt to win in the highly competitive enterprise space. This choice mainly comes down to where the company has a moat that can result in durable profit margins.
How Market Dynamics Affect the Models
First, let’s explore the dynamics of the consumer market. Consumers, by and large, make buying decisions not based on performance or objective metrics, but instead based on “vibes”. You can improve the vibes for a consumer by improving brand positioning (i.e., make the consumer feel a certain emotion from using your product) or by improving the user experience (UX) and user interface (UI) of your product (i.e., make the product more enjoyable for the user).
OpenAI’s lead in consumer usage stems primarily from precisely these areas, with its extremely strong branding and UI/UX improvements in its chat interface versus the competition. OpenAI had a strong, multi-year lead due to its first-mover advantage, providing its “ChatGPT” brand with significant mindshare in the consumer base. In addition, since the release of the original ChatGPT, OpenAI has focused strongly on the web and mobile chat experience. With features like memory and ChatGPT Projects, OpenAI has introduced a high level of personalization for users of the app, thereby creating a high switching cost moat — if you switch to Claude or Gemini, you can’t take ChatGPT’s memories or projects with you. This instantly makes the competing consumer apps less appealing to users in the same way that users of Spotify are reluctant to shift over to Apple Music once they have built up a library of playlists that they enjoy.
Hence, to improve consumer market share, OpenAI will need to continually pull the two levers of brand positioning and UI/UX improvements. Models can’t really improve brand positioning much, as that is more a function of marketing, so the main pressure on the model side of the equation will come from the UI/UX push. This pressure results in making models that are simpler and more enjoyable to use.
Now we’ll shift our view to the enterprise market. Businesses, unlike consumers, strictly focus on return on investment when allocating capital expenditures. These ROI calculations will essentially have four inputs when it comes to LLMs:
The API cost per million tokens
The number of tokens needed to solve a task
The value of that task
The performance of the LLM on that task
We can then model the ROI of using an LLM as follows:
So, from the above, we can see that the only levers that LLM providers can pull to improve the ROI calculations for a company are:
Decrease the cost per million tokens for the API
Decrease the number of tokens needed to solve the task
Increase LLM performance on the task
Given the pressure from open source contributions (e.g., DeepSeek, Kimi, and Qwen), closed source model providers will never be able to compete on #1. #2 also runs counter to the current scaling of AI models — to increase test-time compute (and thus make the LLM useful for more difficult tasks), we by definition have to increase the number of tokens used. Hence, LLM providers competing in the enterprise have started to converge on #3 — improving LLM performance on the given task.
Now, there are two additional levers that an LLM provider can pull to improve the performance of the model on a specific task:
Make the model smarter overall
Customize the model for that task
Broadly, Google has taken the first approach, with Gemini models consistently leading the pack in intelligence (particularly the new Gemini 2.5 Pro Deep Think model). OpenAI would struggle mightily to compete along this dimension because Google has such massive advantages in terms of scale — it has access to ridiculous amounts of compute and has indexed virtually all of the world’s data. Having a lead in algorithms is not a durable moat due to the speed of diffusion of inventions in Silicon Valley, and since model performance is a function of algorithms, data, and compute, Google will maintain a decisive lead here.
Meanwhile, Anthropic has taken the second approach, specializing its models for code using targeted reinforcement learning and building the Claude Code agentic harness. This is the lowest-hanging fruit for specialized models, given that this is the domain in which today’s LLMs perform best. Since Anthropic already has a large lead here, this then leaves OpenAI with two choices: find a less obvious niche for which it can start customizing its models, or compete directly with Anthropic in the coding space, where its competitor already has a large advantage.
From the above analysis, we can see that OpenAI has a large lead in the consumer market with durable moats, and that in order to improve those moats, OpenAI would need to improve the UI/UX of its models by making them simpler and more enjoyable to use. By contrast, to compete in the enterprise market, OpenAI would need to either produce the smartest model (where it is at a disadvantage compared to Google) or start customizing its models for targeted use cases (where it is at a disadvantage compared to Anthropic in the most obvious market of coding agents).
Conclusion - GPT-5 as AI for the Common Man
Now, let’s wrap up this argument.
We have already seen that OpenAI has a large and commanding lead in the consumer market, with a low and shrinking market share in the enterprise market. Now we have also shown that it has solid, defensible moats in the consumer market, and it is at a strong technical disadvantage in the enterprise market. We have also established that prioritizing consumers means improving model UI/UX, while prioritizing enterprise means improving model performance and specialization. Lastly, from the opening paragraphs, we have established that OpenAI deliberately did not make the highest-performing model possible.
Instead, they prioritized reducing hallucinations and streamlining the model selection process in ChatGPT. Both of these changes significantly improve the consumer experience, as confabulations can destroy consumer trust and erode brand advantages, while the old model picker with nearly 10 different models intimidated new users and caused high cognitive load when using the app.
As such, the logical conclusion is that OpenAI has chosen to prioritize consumers over enterprise, and GPT-5 is the result of this.
Hence, over the coming years, don’t expect OpenAI to consistently lead in model performance as they have over the past 3 years. Instead, look for continuing improvements in the usage experience of ChatGPT. If you want to find the best models overall or the best coding models, you’ll probably need to look to Google and Anthropic, respectively.