
The Unreasonable Effectiveness of LLMs in Mathematics
A journey into the mathematician's unconscious


In July 2024, DeepMind unveiled AlphaProof — an AlphaZero-inspired agent that constructs mathematical arguments in Lean, a programming language for proofs. It broke new ground in mathematical performance, achieving a silver medal in the 2024 International Math Olympiad.
One year later, in July 2025, OpenAI announced that they had achieved a gold medal in the 2025 International Math Olympiad using a raw LLM — no reinforcement learning in Lean space, no translation between natural language and formal proof languages. In the span of a few weeks, this same model would go on to add a gold medal at the International Olympiad in Informatics and a 2nd place finish at the AtCoder World Tour Finals to its achievements.
How is it possible that a general LLM, one that operates in natural language and would be just as comfortable answering questions about lasagna recipes in ChatGPT as it is scoring a gold medal in the IMO, could defeat a model that was custom-made to solve math problems by thinking directly in proof space? And is the current LLM architectural paradigm enough for us to solve mathematics?
A Brief Explanation of AlphaProof

AlphaProof is an LLM- and reinforcement-learning-based approach to mathematical proof generation published by DeepMind in November 2025 (with its initial announcement in July 2024).1 The model was inspired by AlphaZero, the successor model to AlphaGo & AlphaGo Zero, which taught itself to play chess, shogi, and Go purely through reinforcement learning (RL) from self-play
The AlphaProof research team began by translating mathematical problems from natural language into Lean, a formal proof language that allows users to build mathematical arguments through explicit axioms, theorems, and deductive steps. Proofs in Lean are built up one step at a time by applying actions (called tactics) to change the current proof state. Lean guarantees that each step must be logically rigorous and consistent — if not, the proof won’t compile.
To generate a sufficiently large dataset to learn from, a Gemini-based LLM (known as the formalizer) was trained to translate natural-language mathematical statements into Lean (see the figure below for an example).

With this setup in place, constructing math becomes a game-like RL environment, where the state is the current proof status, the set of actions is the set of possible Lean tactics, and the reward for each action is -1 (encouraging shorter proofs, since we aim to maximize the cumulative reward).
AlphaProof gets its tactics from the combination of a prover agent and a search algorithm inspired by AlphaZero. The prover agent is a 3-billion-parameter encoder-decoder transformer model that suggests tactics to apply next (given the current prompt state) and estimates their expected cumulative return (that is, what I would expect my total reward to be starting from the proof state that this action will take me to and continuing until I complete the problem). The tree search algorithm explores sequences of actions suggested by the prover agent and evaluates their results.
The prover agent learns by training on the Lean problems generated by the formalizer. It, along with the tree search algorithm, generates attempted proofs and receives a learning signal depending on whether a valid proof is found or the agent times out during the search.
The prover agent + tree search algorithm approach allows us to scale along two axes: training time for the prover agent and test-time computation for the tree search algorithm. This dual-scaling enables strong performance on held-out IMO problems, as shown in the table below. When we increase tree search time from 2 TPU minutes per problem to 12 TPU hours per problem, we see validation accuracy jump from 33.2% to 43%.7%

However, from the above, we can see that the paper uses another scaling axis — namely, test-time RL (TTRL).
The way this works is that, for challenging problems, a variant generator can create hundreds of thousands of distinct yet similar formal problems for the proof network to continue training on. The prover will then learn from these similar examples, updating its weights as it gets rewards for completing proofs. After TTRL has been executed, the prover agent now “knows” substantially more about the problem area adjacent to the problem we actually care about, thereby improving its accuracy.
Thus, to achieve the highest levels of performance, the AlphaProof system needed to overfit on new data that was extremely similar to the questions asked. It did not succeed out of the box at the IMO, even after training on ~80 million formal problems. In particular, on the IMO holdout set (as seen in the table above), AlphaProof required a 4-order-of-magnitude increase in compute budget to go from a 33.2% to a 58.3% success rate. The final 4.4 percentage points of performance (from 53.9% to 58.3%) required an additional order of magnitude in compute (from 3,000 TPU minutes per problem to 30,000 TPU minutes per problem). The paper explicitly states that “each of these solutions required 2–3 days of (test-time RL) TTRL, demonstrating substantial problem-specific adaptation at inference.”
The main takeaway of all this is the following: AlphaProof used a highly math-specific RL environment, along with supporting models (e.g., a formalization system and a variant generator), and a formal proof language to achieve its groundbreaking theorem-proving results. It did indeed set a state-of-the-art in mathematical benchmarks such as the IMO; however, despite the scaffold already being highly specific to the problem, it was still insufficient, with the model still requiring multiple TPU days of test-time RL and hundreds of TPU days of tree-search time per problem to achieve optimal performance. Thus, although highly performant, AlphaProof was not a general-purpose theorem-proving system — it still required substantial overfitting and custom software to be useful.
GPT-5.x and The Mathematician’s Mind
While AlphaProof performed well with its highly-custom scaffold and approach to overfitting problems, OpenAI’s IMO Gold model blew it out of the water without all of these math-specific bells and whistles.
How is this possible? How can a general-purpose system perform so much better than an application-specific system? And why have all the large labs moved away from these application-specific systems in the intervening ~2 years since AlphaProof’s release?
The answer lies in the subconscious mind.
Jacques Hadamard, one of the great mathematicians of the 20th century, published The Mathematician’s Mind: The Psychology of Invention in the Mathematical Field in 1945. Building on Henri Poincaré’s 1908 lecture titled L’invention Mathématique (Mathematical Invention), he interviewed several of the greatest living mathematicians & physicists at the time (including George Polya, Claude Lévi-Strauss, and Albert Einstein) and assessed how their process of mathematical discovery felt from a phenomenological perspective.2 He wanted to answer the following question: What is occurring in the minds of our greatest mathematicians when they make new discoveries?
The answer Hadamard found, synthesizing results from these interviews, was that mathematical discoveries arise from the interplay between conscious and unconscious processes. And, in particular, the idea for the proof tends to start in the subconscious.
…let us remember that every mental work and especially the work of discovery implies the cooperation of the unconscious, be it the superficial or (fairly often) the more or less remote one; that, inside of that unconscious (resulting from a preliminary conscious work), there is that starting of ideas which Poincaré has compared to a projection of atoms and which can be more or less scattered ; that concrete representations are generally used by the mind for the maintenance and synthesis of combinations. This carries, in the first place, the consequence that, strictly speaking, there is hardly any completely logical discovery. Some intervention of intuition issuing from the unconscious is necessary at least to initiate the logical work. [emphasis mine]
Hadamard asserts that no mathematical discovery is purely logical. The unconscious mind, in all cases that he examined, played a crucial role in the development of rigorous mathematical arguments. This role, and the handoffs between the subconscious and conscious minds, were distilled by Hadamard into the following framework for mathematical discovery:
Preparation (primarily conscious) — the conscious mind focuses on a problem for an extended period of time, collecting relevant information and trying out several avenues for solution
Incubation (primarily unconscious) — the unconscious mind, directed in its goals by the focus of the conscious mind in the Preparation stage, sets to work searching for high-level solutions. This is where the bulk of problem-solving and discovery is actually done. The unconscious mind is better at viewing the problem as a “whole” and at uncovering unexpected insights and connections than the conscious mind. The unconscious mind evaluates proposed solutions based on aesthetic criteria.
Illumination (primarily unconscious) — an idea generated by the unconscious mind that satisfies the unconscious criteria springs forth into the conscious mind
Verification (primarily conscious) — the conscious mind sets to work translating the unconscious’s idea into formal mathematical language and verifies that it is logically correct.
Thus, we can see that the unconscious mind is actually responsible for generating the proof structure. The conscious mind just sets the scene during the Preparation stage and verifies that suggested proof structure during the Verification stage. But it does not produce the critical insights regarding the proof’s structure that actually lead to the discovery itself. As a result, we can say that the discovery process is decidedly not rigorous.
AlphaProof’s downfall was that it was designed to act like the rigorous conscious mind — every step must be constructed rigorously and logically consistent with previous steps, and the proof is built up step by step. In this manner, AlphaProof acts at a local level with the prover trying to find the best next incremental step in a proof, whereas the mathematician’s unconscious mind works at a global level by identifying a full proof sketch all at once. Only then does the conscious mind fill in the rigorous details.
Based on this insight, we see that an AlphaProof-like system is most closely aligned with the Preparation and Verification stages in Hadamard’s framework. It completely omits the Incubation and Illumination phases, where the actual work of discovery occurs.
OpenAI’s gold-medal-winning model, as a standard LLM deployed for mathematical use cases, represents a new paradigm in mathematical reasoning that relaxes AlphaProof’s constraints on only following rigorous thought. It enables messier, higher-level reasoning in the language space rather than in the Lean-verified proof space. The system can think through and mentally pressure-test high-level approaches & proof sketches, rather than being forced to focus exclusively on granular proof steps, as in AlphaProof.
To demonstrate this, I provided GLM 5.1 with question C4 (a medium difficulty combinatorics problem) from the 2024 International Math Olympiad. By using an open-source model, we can see the full reasoning trace and how its thought process leads to its final answer.
In the excerpt provided below of the model’s reasoning trace, you can see how messy and non-rigorous the thinking truly is. The model is jumping around in conceptual space, backtracking frequently, and probing different high-level directions.
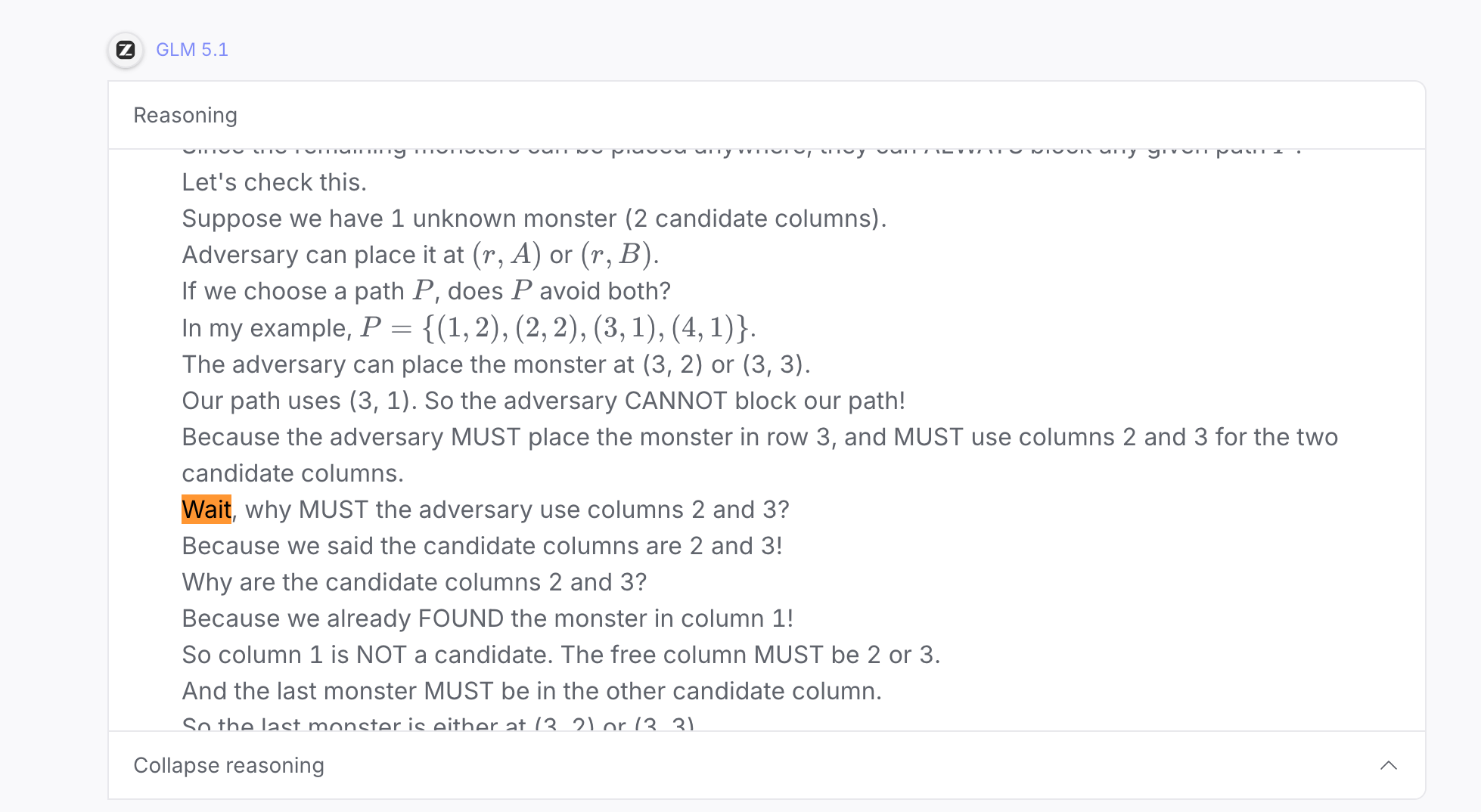
We can see from the above example that this brings us closer in line with the Incubation and Illumination phases of Hadamard’s process — the LLM is able to search for high-level solutions and make jumps that are not logically rigorous and are not incremental (in the sense that they do not need to be at the scale of a single tactic in Lean). The model is free to jump around in natural language between several, potentially unrelated concepts. It is only forced to converge on a rigorous, verified solution at the end of its answer once one of the high-level solutions satisfies its aesthetic sense.
This relaxation of constraints on the thinking process also explains how the system can generalize across domains — the model does not need all the math-specific scaffolding and so can learn a more general process of discovery. This process, as outlined by Hadamard, is not limited to math (as evidenced by Einstein's inclusion in the group). In fact, it seems to me that discovery in any domain that can culminate in a Verification step will follow this overarching process. And we do see this in the success that OpenAI’s model enjoyed at the IOI and AtCoder competitions shortly following its gold medal at the IMO.
So, is math (and all other easily verified domains) solved with this paradigm?
Not quite. While OpenAI’s gold medal LLM represents a meaningful improvement over AlphaProof in bringing AI proof systems into alignment with how mathematicians actually think, there is still a glaring gap: the model is required to reason in language space and produce one token at a time. Although this allows for broader, less rigorous thought than AlphaProof, it is still far more constrained than Hadamard’s description of the unconscious. Specifically, Hadamard asserts that, in addition to being non-rigorous, unconscious thought is often not even interpretable. He says that at this stage, all mathematicians think without language or precise symbols, and many do not even use clear images. The ideas themselves are vague, amorphous, and global. Hadamard says:
Practically all of [the mathematicians interviewed]… avoid not only the use of mental words but also, just as I do, the mental use of algebraic or any other precise signs; also as in my case, they use vague images.
This differs substantially from LLMs, in which each thought has a fixed amount of computation applied to it, after which that thought must then be made concrete in the form of a token. As a result, current systems are limited in how closely they adhere to Hadamard’s discovery framework. This fundamentally limits how creative they can be — the more we force thoughts to be interpretable and legible, the less unexpected and amorphous they will be, and thus the less they will approximate the unconscious mind.
The Reasoning Paradigm of the Future
As Hadamard astutely observed, true discovery occurs at the subconscious level rather than through rational, conscious processes. When moving from AlphaProof to OpenAI’s IMO Gold model, we took one step towards the unconscious — from the uber-rational realm of Lean and step-by-step proof construction into the messy, unrigorous world of natural-language thought.
Although this thought is messy, it is still articulable and thus operates at a level above what we call the subconscious. Reasoning in natural language allows for more flexibility than reasoning in Lean, but we know that mathematicians don’t reason in language at all during the Incubation and Illumination steps.
If the bottleneck is the token itself — the forced collapse of each thought into a discrete, legible symbol — then the natural question is whether we can let models reason before that collapse happens. What would it look like for an LLM to think in a medium richer than language?
For LLMs, the level below token-based thought is embedding-based thought. A model's actual computation lives in embedding space before it's projected down into the vocabulary — just as the mathematician's thoughts live in the unconscious during Incubation before being projected into the conscious mind during Illumination. Each token is a lossy compression of a much higher-dimensional internal state.
Recall Hadamard's observation that mathematicians reason in vague images rather than precise signs. An embedding is, in a loose sense, exactly that: a vague, high-dimensional representation that has not yet been forced into a precise sign.
Thus, rather than forcing the model to output its reasoning in token space, we can allow it to reason in this much higher-dimensional embedding space found within the model's internals. This allows for much more abstract and “unconscious” thought than standard token-based reasoning does, aligning more closely with Hadamard’s concept of unconscious thought.
ByteDance implemented this idea in their November 2025 paper titled “Scaling Latent Reasoning via Looped Language Models,” which developed a model family called Ouro.3 This model family is what is known as a “looped language model” — that is, rather than outputting a token once the language model reaches the last layer in its computation graph, it loops back on itself by ingesting the embedding from layer N as new input for layer 1 (see leftmost diagram in the image below).

As a result, the model can learn to reason deeply about tokens without first converting them to language space. Moreover, the ByteDance team integrated this reasoning process directly into pretraining and implemented a mechanism for the model to determine when to stop looping during inference based on a predicted exit probability. This allows the model to more closely integrate its reasoning capabilities with its world knowledge (since it is trained during the pretraining stage), as well as to learn to modulate its reasoning based on the difficulty of the next token.
And, most importantly, this brings the model’s reasoning process much closer to Hadamard’s core Incubation and Illumination steps.
With this setup and its proximity to Hadamard’s Discovery process, a very general-purpose approach to reasoning in verifiable domains, we would expect the model to perform better across a number of benchmarks. And that is precisely what we see. Not only does the model outperform much larger models, but its performance is also less “spiky” — that is, it performs consistently well across many benchmarks rather than experiencing isolated “spikes” in performance on certain benchmarks (see the central and rightmost figures in the image above).
We can see further evidence that this approach improves reasoning in the image below. On the left-hand side of the image below, the authors compared the bits of knowledge memorized by different train models (y-axis) to the number of parameters of those models (x-axis). For each model size, they trained a looped and a non-looped model variant, represented by large and small circles, respectively. You may not have noticed that there are two circle sizes on the graph because they basically overlap exactly for all model sizes. Thus, adding looping does not allow the model to learn more information.
Now, if we turn our attention to the right-hand side of the image below, we can see the performance of a baseline transformer and a looped variant at different sizes on a reasoning-heavy benchmark. The numbers jump off the page — at each fixed model size, the looped model vastly outperforms the non-looped model. More astoundingly, a two-layer looped model substantially outperforms the largest non-looped model (the 12-layer variant in the first row).
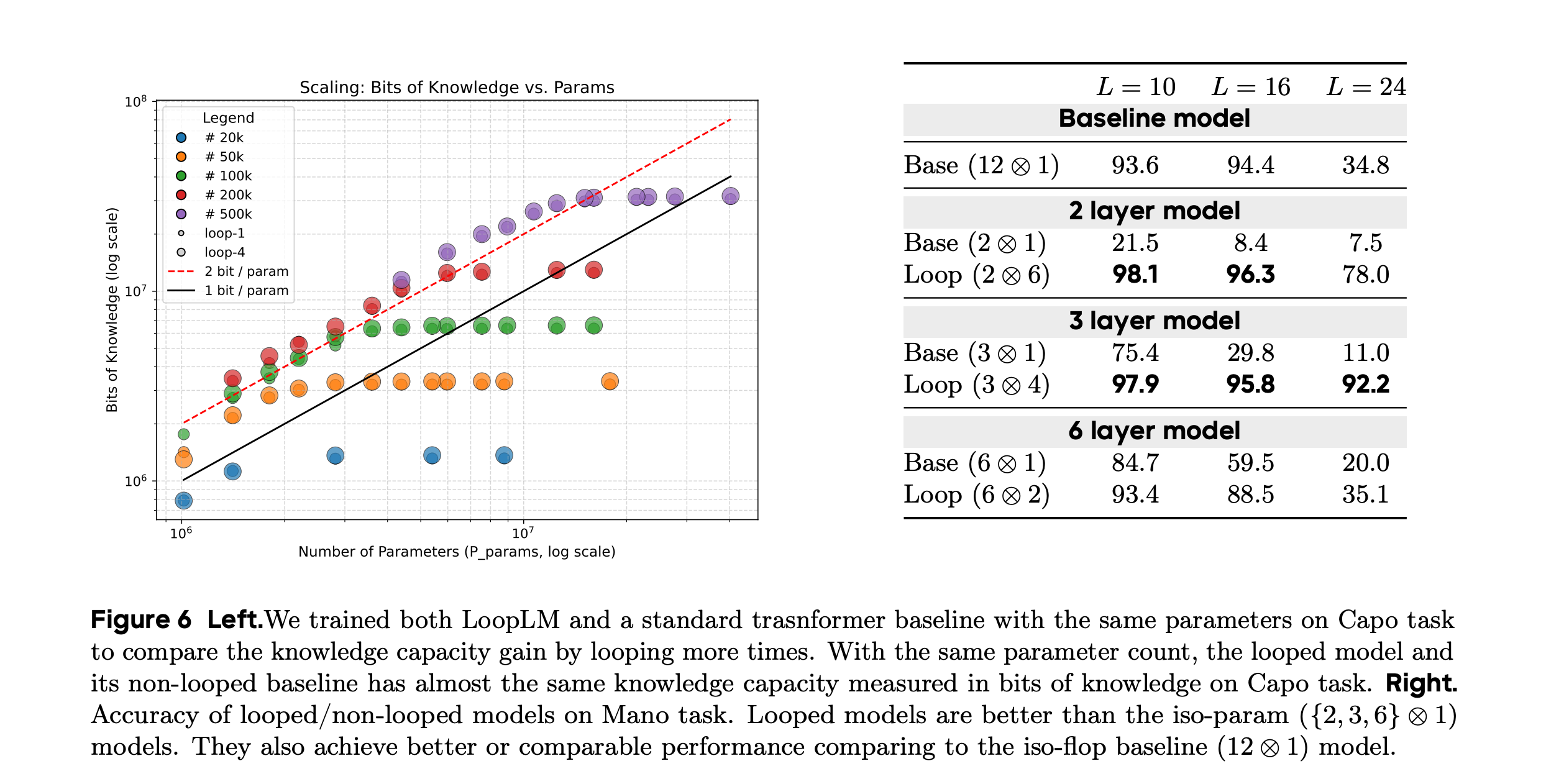
Hence, from the above, we can see that applying an embedding-space loop to language models, thus bringing them closer to Hadamard’s Discovery process, substantially improves reasoning ability. And this reasoning ability seems to generalize better across benchmarks than standard RL on top of language models. As a result, I expect all frontier LLMs to adopt this paradigm if they haven’t already.
Stepping back a bit, there is something quietly counterintuitive about the trajectory of the last two years. AlphaProof tried to make machines do math by forcing them to be maximally rigorous, with every proof built up from one logically rigorous step to the next. It was, in many ways, the purest expression of what we used to think mathematical reasoning was. And yet it hit a wall.
The lesson of OpenAI’s IMO Gold model, and now of looped language models, is that progress has come not from tightening the constraints on machine reasoning but from loosening them. First, we let models think messily in natural language. Now we are letting them think in a medium that isn’t even language. Each step has moved further from the clean, legible, step-by-step ideal. And each step has improved the models.
But loosening the constraints on Incubation only gets us half of Hadamard’s cycle. I’ve spent most of this piece arguing that LLMs are getting better at Incubation and Illumination, and that looped models push them further in that direction. But this leaves out the fact that current LLMs are weak at Verification. They hallucinate proofs, confidently assert false lemmas, and have no reliable internal signal for when their reasoning has gone off the rails. AlphaProof’s step-by-step rigor was, for all its limitations, a genuine Verification engine — every tactic was checked by Lean before the proof could proceed. Standard LLMs lack such a mechanism and are thus often prone to hallucinating results. The IMO Gold result is remarkable precisely because the model managed to produce verifiable outputs despite lacking a built-in verifier.
Thus, the real frontier is synthesis. AlphaProof gave us a formalizer and a verifier but no unconscious. Looped language models are giving us an unconscious but no verifier. Hadamard’s framework is designed to be a loop — when Verification fails, the mathematician returns to Preparation with new information about why it failed, which reshapes the next round of Incubation. The system that finally closes this loop will be the first one to actually instantiate Hadamard’s full cycle rather than just its generative half.
This, I think, is the actual research agenda for the next few years, and it has two halves that have to advance together. On one side, we need to keep deepening the unconscious by pushing latent-space reasoning further, scaling up looped architectures, and figuring out how to train them with the kinds of reinforcement signals that sharpen aesthetic judgment. On the other, we need to build formalizers and verifiers for a broader range of fields, so that the unconscious can receive concrete feedback from a Verification step. Neither half is sufficient on its own, as the unconscious without a verifier can drift into hallucinations, while the verifier without an unconscious is too rigid to make true intellectual leaps. A synthesis of both is required.
What this looks like concretely depends on the field. For mathematics, both halves are nearly in place. The unconscious is arriving via looped language models, and the verifier already exists in the form of Lean. All we need to do is use AlphaProof’s Formalizer to convert the Looped Language Model output to Lean, and we’re good to go.
The more difficult question is what we do in fields that don’t already have a Lean. The unconscious half seems to generalize quite well, judging by the less spiky benchmark results from the Looped Transformer paper. But the verifier half does not generalize. Instead, it has to be built field by field. And what counts as a verifier in one domain looks nothing like what counts as a verifier in another.
In physics, building the verifier means investing in experiment automation. That is, robotic labs that can run, measure, and report on experiments proposed by a latent-reasoning model, closing the loop between hypothesis and data without a human in the middle. In biology, the same logic points to high-throughput assay platforms that can test a model’s proposed interventions at scale, with the same feedback loop into the unconscious. In economics and the social sciences, the verifier half has to be weaker, such as large-scale simulation environments, prediction markets, or structured forecasting tournaments that can at least provide a noisy verification signal where a clean one is impossible. But even a noisy verifier may be enough to close the loop, so long as the unconscious half is there to propose hypotheses worth testing in the first place.
Hadamard told us in 1945 that the real work of discovery happens in a place that is neither rigorous nor articulable, and that the conscious mind’s job is to set the stage and then check the work afterward. Looped language models are finally giving us the unconscious that Hadamard envisioned. The next paradigm wires the verifier into the output of the looped language models, closing the loop on Hadamard’s Discovery process. The fields where we can build both halves are the fields where Hadamard’s full cycle will finally run on a machine and where we should expect AI progress to accelerate most dramatically in the coming years.
Hadamard, J. (2020). The Mathematician’s Mind: The Psychology of Invention in the Mathematical Field. Princeton University Press.