


Series Introduction
Recently, the announcement of DeepSeek-R1 shook the AI world, as an open source project managed to match the performance of OpenAI's state-of-the-art API, o1, within months of its release. The market reacted vehemently to this news, with Nvidia's stock dropping 18% in a single day. AI researchers, engineers, and commentators alike took to Twitter/X to share their thoughts on DeepSeek-R1's implications for the AI industry and the United States, with many asserting that the age of American AI had come and gone in a flash, with China now firmly taking the lead.
But were these takes correct?
In order to dissect the true implications for the world going forward, we first need to understand DeepSeek-R1 on a fundamental level - what it is, what it does, how it works, and what key innovations it introduced. This blog post series will aim to arm you with that knowledge.
To do this effectively, we are going to start at the beginning of DeepSeek's major papers and work our way forward in time, tracing out the researchers' reasoning and how they arrived at the final design for DeepSeek-R1. This final design included two key components:
An efficient mixture of experts language model base
Reinforcement learning-tuned chain of thought capabilities
In this blog series, we will explore two separate but related series of papers in order to deeply understand the two key components of DeepSeek-R1. First, we will trace the evolution of the mixture of experts architecture from DeepSeek-MOE to DeepSeek-V3, their newest state-of-the-art language model. We will then turn our attention to reinforcement learning-tuned chain of thought, beginning with the seminal DeepSeekMath paper and working our way forward to the current AI darling - DeepSeek-R1.
With this strong foundational knowledge of the theoretical underpinnings of DeepSeek-R1, we will be able to separate the hype from the noise. In light of what we've learned from these paper deep dives, this blog series will conclude with an analysis of the implications of DeepSeek-R1 from several perspectives:
Technological progress
AI market dynamics
Geopolitical risks
By the end of this series, you will have a clear, evidence-based understanding of DeepSeek-R1—what makes it powerful, where it stands relative to its competitors, and what its long-term impact might be. As the AI landscape continues to shift at an unprecedented pace, cutting through speculation and focusing on the fundamentals will be key to making sense of the road ahead. Let’s dive in.
Note: This post is part of the “Understanding DeepSeek” Series:
[This article] Understanding DeepSeek Part I: DeepSeekMoE
[Upcoming] Understanding DeepSeek Part III: DeepSeekMath
[Upcoming] Understanding DeepSeek Part IV: DeepSeek-Prover-V1.5
[Upcoming] Understanding DeepSeek Part V: DeepSeek-V3
[Upcoming] Understanding DeepSeek Part VI: DeepSeek-R1
[Upcoming] Understanding DeepSeek Part VII: Implications for the AI Industry and the World
Paper Summary
Mixture-of-experts (MoE) models are an extension of the standard transformer architecture in which a collection of expert modules (typically feed-forward networks) each learn to specialize in different aspects of the data. For a given token or input, only a subset of these specialized experts is activated, allowing the model to dynamically focus its computation on the most relevant components. This selective activation enables MoE models to achieve a high effective capacity—since many different specialists are available—while maintaining computational efficiency, because only a limited number of experts actually process each input. As a result, MoE approaches excel at capturing diverse patterns, efficiently scaling model size, and flexibly adapting to a wide variety of tasks.
Standard mixture-of-experts models, used prior to DeepSeekMoE, typically rely on selecting the top K experts (often 1 or 2) out of N possible experts for each token in a sequence. While this approach does reduce computational load—since only a small fraction of experts are activated—it also forces those few activated experts to capture all aspects of the token, including common linguistic structure that is often duplicated across experts. Consequently, an enormous portion of each expert’s capacity is spent memorizing redundant information, leaving less room for true specialization.
DeepSeekMoE improves upon the standard MoE architecture, solving this redundancy problem by:
1. Using a larger number of smaller experts (Fine-Grained Expert Segmentation)
Instead of a few large experts, DeepSeek splits capacity into many more experts, each of which is smaller in dimensionality. The model then increases the number of selected experts by the same factor, creating a dramatically larger space of potential expert combinations. Despite this combinatorial explosion, the overall parameter count and per-token activated parameters remain exactly the same as in a conventional MoE setup—meaning we gain richer representational capacity without paying extra in total parameter count or computational cost.
2. Separating Experts into Shared and Routing Experts
DeepSeek also partitions its experts into two sets. The shared experts, which are always activated for every token, learn the broad “common knowledge” required by all inputs (e.g., syntax, high-level semantics). The routing experts, by contrast, are only activated if they are relevant to a specific token, allowing them to focus on niche or domain-specific information. This further decreases redundancy and promotes parameter efficiency: shared experts handle language “fundamentals,” while routing experts handle specialization.
3. Load Balancing Through Additional Loss Terms
Finally, DeepSeek addresses load balancing in two senses. It enforces a roughly equal usage of each active routing expert across tokens—ensuring no single expert is under- or over-utilized—and distributes the experts themselves across multiple GPUs to avoid hardware bottlenecks. Both of these aims are achieved by incorporating new balancing terms into the training objective.

Taken together, these modifications produce a model that is both parameter-efficient and highly flexible. By boosting expert variety, removing needless duplication, and balancing the workload across experts and devices, DeepSeekMoE provides a substantially more effective way to leverage MoE architectures—achieving greater specialization and capacity without increasing the overall parameter footprint.
Let's dive in deeper into these three optimizations now and see how they alter the standard MoE transformer architecture.
Standard Mixture of Experts Models
In standard MoE architecture, expert layers will typically replace the feed-forward layer that occurs after self-attention. Experts can be thought of as a set of N feed-forward layers that are structurally identical to the original feed-forward layer. Only a subset of these N possible feed-forward networks will be activated for any individual token, with many prior MoE architectures selecting 1 or 2 of these N possible networks for a given token.
Whether or not a network is activated is determined by taking the dot product of the output of the attention layer for that token (i.e., the hidden vector for token i) with the centroid of the current expert. We then take the softmax of this value to force it into the range of 0 to 1. You can think of this like an attention score computed over the experts instead of the tokens - we want to see which expert aligns most closely with the current token under consideration. These scores are computed for each expert, and then the experts are ranked according to this score. The top K (usually 1 or 2) experts are selected based on this ranking, and the token embeddings are then passed to those feed-forward expert networks.
The output of these experts is added together alongside the initial hidden state for the token (i.e., the token vector prior to the application of the experts). This produces the final output for the given layer.
The major obstacle with this approach is the following: since most prior MoE models only selected the top 1 or 2 experts for each token, the selected expert(s) must capture everything about a given token, including redundant information such as language structure. This wastes a large amount of the model's capacity to learn useful information, forcing the weights of each expert to memorize redundant information that is already captured by the other experts.
Fine-Grained Expert Segmentation
One of DeepSeek's solutions to the redundancy problem is to make experts smaller but more numerous. That is, the DeepSeekMoE approach reduces the dimensionality of each individual expert's feed-forward network (and therefore its computational cost and representational capacity) by a factor of 1/m compared to the network's standard feed-forward networks. Correspondingly, it increases the number of total experts by a factor of m and the number of selected experts by the same factor of m. This results in the same number of parameters for the model on net, but allows for substantially more variety when selecting the experts to use for a specific token.
We can see this increased variety when examining the combinatorics of the expert space. Suppose our standard feed-forward network has hidden dimension 4096, and our standard mixture of experts model uses 8 of these experts in total, with 2 selected for any given token. This results in the following number of possible expert combinations for each token in the standard mixture of experts model:
Now, using the DeepSeekMoE architecture, suppose we have m = 8. That is, we are going to increase our number of experts by a factor of 8 (and reduce the hidden dimension by a factor of 1/8). This gives us a hidden dimension of 512 per expert, with 64 total experts and 16 experts selected for any given token. This results in the following number of possible expert combinations for each token in the DeepSeekMoE version of the model:
That is, we go from 28 possible expert combinations to nearly 489 trillion possible expert combinations! This allows for significantly more specialization across experts and much more variety in knowledge application on a token-by-token basis. Astonishingly, even with this huge increase in variety, the number of tokens stays exactly the same! The number of total parameters in each model is given by:
Similarly, the number of parameters activated for any given token is exactly the same:
Hence, we get basically a free lunch here - significantly higher representational capacity in our model with the same number of parameters used!
Shared Experts
Another approach DeepSeek took to avoid capturing redundancy in its experts is to segment the expert population into two groups: shared experts and routing experts.
Shared experts are always activated, regardless of the input token. This incentivizes these expert modules to capture common knowledge relevant to all queries (e.g., language semantics). By contrast, routing experts are only activated if the token is relevant to the expert, as described in the "Standard Mixture of Expert Models" section.
That is, the initial mN experts are split into two groups: K_s shared experts and K_r = mN - K_s routing experts. All of the K_s shared experts are activated for all tokens, while a subset of the K_r are selected for each token. Mathematically, this looks like the following:
Hence, we can see that the hidden vector output of token t at layer L always uses all of the shared experts (denoted by the first summation in the equation) and always includes the residual (denoted by the last term). The middle term, representing the routing experts, includes a gating factor that controls which experts are turned on for any specific token. In particular, the gating factor is the output of a softmax if the expert ranked in the top mK experts. Otherwise, it is 0. As a result, not only do we eliminate most of the possible experts (thereby greatly reducing the number of active parameters), we also weight the final output based on how close each chosen routing expert is to the token. In other words, the more a chosen routing expert "knows" about a topic, the more heavily we weight its opinion.
This setup allows the routing experts to ignore the redundant information captured by the shared experts and instead focus on learning concepts and information that are relevant to their area of specialization. This promotes parameter efficiency in the model, as each marginal parameter added to the routing experts will be encouraged through the learning process to acquire information that is distinct from the existing parameters.
Load Balancing
Now that we have a better-designed MoE network with fine-grained experts and expert sharing, there still remains one major challenge to ensure the parameters are used maximally - we need to load balance requests across the available experts. Essentially, our goal is to force each token to attend to the outputs of the mK chosen routing experts roughly equally. This makes certain that, when we activate routing expert parameters to process a particular token, all of the activated parameters are contributing meaningfully to the output. As a result, we maximize the utilization of the MoE architecture.
In addition to load balancing across experts, we would like to load balance across devices. Experts are typically stored on many separate GPUs, since these models are too large to fit in the memory of a single GPU. Given this fact, we would like the chosen experts for a token to be evenly spread across devices, thus preventing overloading of any single GPU.
These two goals are achieved by DeepSeekMoE through introducing two new terms to the loss function.
Results and Key Takeaways
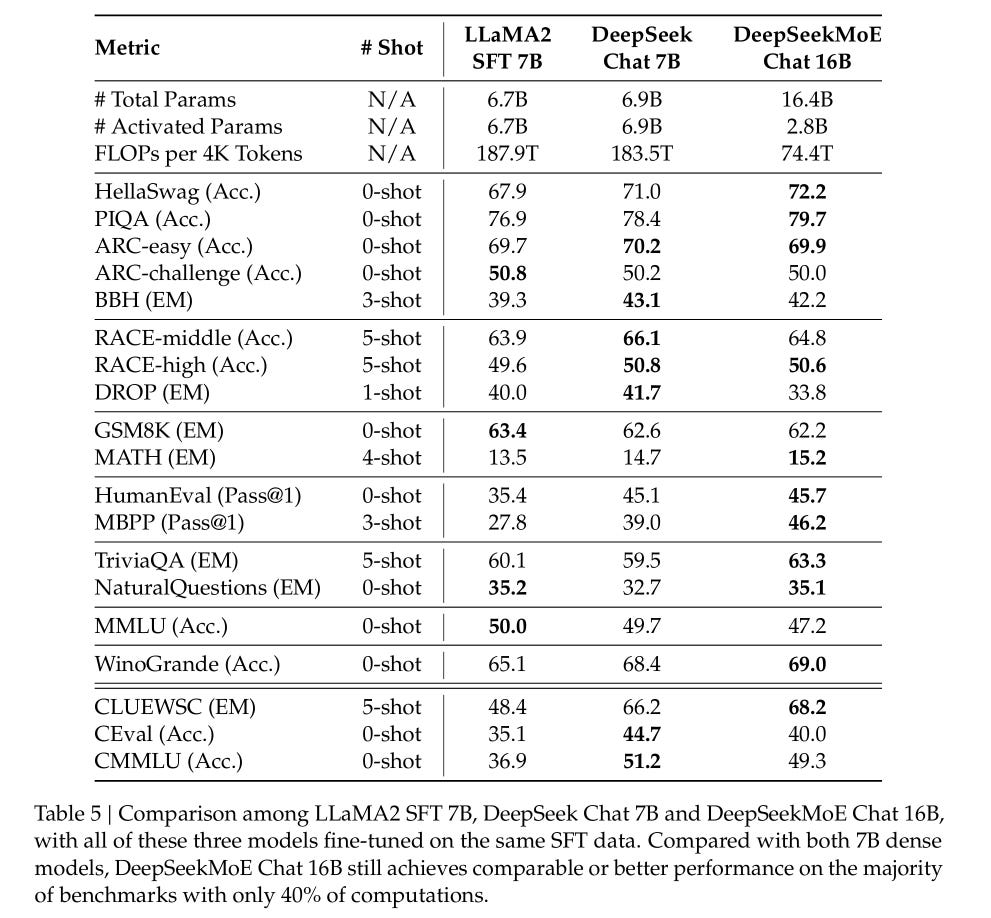
With the above optimizations, DeepSeek was able to mitigate many of the most challenging problems facing MoE models. Together, fine-grained segmentation, shared experts, and load balancing work to maximize the amount of unique, useful information stored in a given set of parameters. As a result, DeepSeekMoE is able to outperform models with fewer active parameters. Below, we can see that DeepSeekMoE outperformed LLaMA2 7B (a dense model that does not use any experts) across a number of benchmarks with fewer than half of the active parameters.
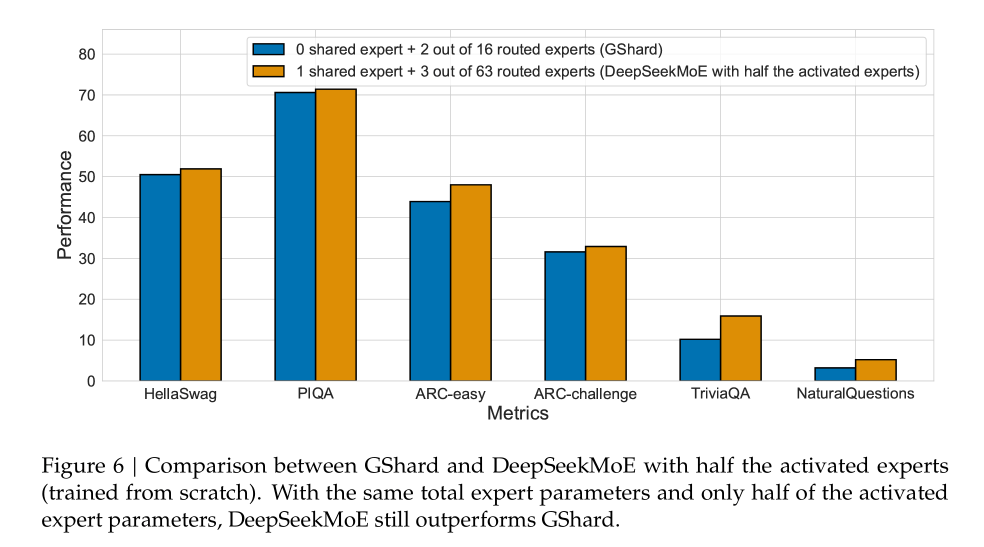
When compared to another mixture of experts model, GShard, we see that DeepSeekMoE again outperforms it with the same total parameters and only half of the activated parameters.
In sum, DeepSeek's optimizations for the MoE architecture served to substantially expand the possibilities for local and edge inference. Since only a small percentage of the model's total parameters are active for any given token, during inference, the model's performance requirements are much closer to those of a small, weak model. However, its output quality matches that of a large, well-trained dense LLM. This innovation was critical for laying the groundwork towards DeepSeek-R1, ensuring that state-of-the-art base LLM performance would be possible for smaller models.