
Reading Recap: Q1 2026
Brief reviews of the books and papers I read from Jan-March 2026


The idea for this series started with a tweet I made a few weeks ago.
Then, a couple of weeks later, Anna Gát posted a fantastic essay titled The Sovereign Reader , which contained this wonderful quote:
The truth is the more unique and personalized the books you read, the more original a thinker you will become. This, in short, is how you become you. I am a strong post-Hegelian believer in the personal duty of coming into our full being throughout our lives. Other than finding a fitting occupation and worthy life companions, cultivating your own mind is the prerequisite for building an existence for yourself that is truly yours.
This quote connected with the ideas I’d been toying with in my earlier tweet — many of the most interesting people in the world have likely cultivated themselves and their minds in this sense, and thus, peering into their bookshelves would help us understand the inner self that they cultivated. And I would kill to see what they read, when they read it, and what they thought of it!
So I thought, “why not be the change you want to see in the world?” and decided to share what I’m reading much more often (and hopefully this inspires some people far more interesting than me to also share what they’re reading!)
The result is this article, the first in a quarterly update series in which I list, in chronological order, all the books I’ve completed this quarter. I’ll also list some of the notable papers I read in the quarter, though this list won’t be exhaustive, since my skim-to-deep-read ratio is much higher for papers than for books! Some of these papers and books will have brief reactions and/or reviews accompanying them if they especially stood out to me.
I hope you enjoy!
Books
#1. Claude Hopkins, Scientific Advertising
A pretty useful book capturing the earliest forms of approaches now taken for granted in the advertising industry — namely, taking a scientific approach to advertising through A/B testing aggressively and tracking conversions tied to each ad type, rather than trying to “plan” ad creative without customer feedback.
Interesting to read if you are in/adjacent to the ad space. Also contains useful nuggets on how to think about advertising. The one concept that really stuck with me is that advertising is not for building brand awareness, getting your name out there, or any other ancillary goal. Instead, it is just sales at scale. As a result, when writing your ads, you should imagine that you are standing in front of one of your target customers and trying to sell him or her your product. What would you say to this one person? How long would your pitch be? What would you do to legitimize yourself, your company, and your product to this one person? Think through these questions and write your ad based on your answers.
#2. Alexandre Dumas, The Count of Monte Cristo
I don’t really know where to begin with this book because I loved it so much. Read it if you haven’t. Re-read it if you have. It hooks you from the first page and doesn’t let go for its full 1,300+ pages.
If there is one theme I can give you that stuck with me through the book, it is an interesting parallel to Crime and Punishment. The protagonists in both books, Edmond Dantès here and Raskolnikov in Crime and Punishment, have these ideas of grandeur, of being a superior man who does not need to obey the laws and customs of inferior men. But when they come into contact with human connection, those ideas fall apart. Dantès wavers in his plans to kill Albert de Morcerf after talking to Mercedes. He also resolves to save Valentine de Villefort after Maximillien Morrel reveals that he is in love with her. These contacts with love and social connection cause him to change his divine mission of Providence and remove some of the suffering he had planned for his enemies. Similarly, when Raskolnikov is alone, he frequently thinks of his superiority to others and hates those around him. But when he comes into contact with others, especially those who inspire tenderness in him, like Sonia Marmeladov or her father when he was dying, he behaves extremely altruistically and without any consideration for his ideals that he is above the common man, and acts in any way that he wants as long as it suits his aims.
To connect both to Nietzsche (who was explicitly influenced by Crime and Punishment and likely influenced by The Count of Monte Cristo) and his conception of the Übermensch, both authors seem to assert that removing oneself from the rest of humanity is necessary to become the Übermensch.
For Dostoevsky, this task is impossible and results in the destruction of the individual who attempts it. We find salvation only by connecting with humanity, not by setting ourselves apart. By contrast, for Dumas, this represents a genuine tension — Dantès is able to set himself apart and does act as a superior man, or Übermensch. And this does bring him fulfillment in some ways (namely, avenging his wrongful imprisonment and his father’s death). However, this choice also precludes his happiness in other ways, as while acting as the Count, he must make choices that hurt those closest to him.
#3. Dan Wang, Breakneck: China’s Quest to Engineer the Future
I found Wang’s now-famous framing of the US as “the lawyerly society” and China as “the engineering state” very illuminating — it is a neat little framework that helps you make sense of the many strengths and weaknesses of each country. However, I thought the most useful part of the book was not its thesis or the framework it introduced, but rather the stories Wang tells throughout. He lived in China from 2017 to 2023, experiencing the country’s rapid economic growth and the way this continually reshaped society firsthand. But he also experienced the early authoritarian turns instituted by Xi Jinping, as well as the COVID-19 pandemic and dramatic lockdown of Shanghai in 2022. Getting an insider’s view of Chinese society in this period was clarifying in a way that the many economic and historical analyses of China are not.
And, of course, Dan Wang’s annual letters are self-recommending for more of this type of writing.
#4. Eric Berger, Liftoff: Elon Musk and the Desperate Early Days That Launched SpaceX
At this point, I’ve read a few books on Elon and listened to many podcasts about him or including him, so there wasn’t a lot in the way of surprises in Liftoff. What this book does well, however, is to impart the feeling of the life-or-death struggle that followed Elon around in those first few years at SpaceX. The company existed on the razor’s edge for essentially all of its early life, and we get to see the intensity with which Elon drove his employees (and himself) to ensure the company survived.
#5. Ali Aminian, Generative AI System Design Interview
Fairly useful for interview prep, pairs well with the other books in the series (Machine Learning System Design Interview and System Design Interview Volumes I & II).
#6. Jacques Hadamard, The Mathematician’s Mind: The Psychology of Invention in the Mathematical Field
In this book, Jacques Hadamard asks the question, “How do the world’s greatest mathematicians and physicists actually make their field-defining discoveries? What is going on inside their heads when they solve these supremely difficult problems?”
Being an elite mathematician himself, Hadamard was able to interview some of the greatest minds of his era to learn the answer to this question. The book compiles a list of vignettes from Poincaré to Einstein, probing the question from different angles, and essentially lands on the following answer — the rational, conscious mind is useful for getting us started on a problem and for verifying an answer once we have it, but the actual work of producing a novel insight is done by the unconscious mind. The discovery process he deduced from his observations, and that he asserts all great mathematical discoveries abide by, is as follows:
Preparation (primarily conscious) — the conscious mind focuses on a problem for an extended period of time, collecting relevant information and trying out several avenues for solution
Incubation (primarily unconscious) — the unconscious mind, directed in its goals by the focus of the conscious mind in the Preparation stage, sets to work searching for high-level solutions. This is where the bulk of problem-solving and discovery is actually done. The unconscious mind is better at viewing the problem as a “whole” and at uncovering unexpected insights and connections than the conscious mind. The unconscious mind evaluates proposed solutions based on aesthetic criteria.
Illumination (primarily unconscious) — an idea generated by the unconscious mind that satisfies the unconscious criteria springs forth into the conscious mind
Verification (primarily conscious) — the conscious mind sets to work translating the unconscious’s idea into formal mathematical language and verifies that it is logically correct.
This book inspired my recent essay, The Unreasonable Effectiveness of LLMs in Mathematics.
#7. Stendhal, The Red and The Black
After reading Crime and Punishment last year, I’ve become slightly obsessed with the crisis in literature and philosophy that Napoleon presented after his meteoric rise and fall in the late 18th and early 19th centuries. I’ll start by giving a brief sketch of how I see the situation and the intellectual crisis that followed.
For the 300 or so years prior to Napoleon, philosophy had been building up to a notion of equality among people. The Enlightenment supercharged this, popularizing ideas about egalitarianism, self-determination, and natural rights. The American Revolution then put these abstract ideas into practice, and was quickly followed by the French Revolution, which sought to put an even more radical version of Enlightenment ideals into practice.
The Enlightenment’s ideas on political philosophy and these two revolutions were both rebelling against the prevailing traditional doctrines of the time. Power and the right to rule were seen as hereditary — God ordained a specific line to rule, and this right was passed down from father to eldest son in an unbroken chain. Moreover, the structure of society itself was seen as a crucial part of any nation. The peasants were meant to be peasants, the rulers were meant to rule. To go against this was to go against the natural order ordained by God.
These two groups were locked in an existential struggle in the late 1700s when Napoleon erupted onto the scene, forever changing the trajectory of the world. Through unparalleled competence, energy, and charisma, he became emperor of France, and then nearly the emperor of Europe. He reshaped society at the high-level scale of large historic battles, as well as at the granular scale of laws, regulations, and standards. By the time of his final defeat, there was not one piece of European life that did not have Napoleon’s fingerprints on it.
His almost-mythic life refuted both groups’ ideals.
The traditionalists asserted that humans can influence history, but that this is only the providence of hereditary kings (i.e., greatness comes from family lineage). The new ideas of the French Revolution hold that humans cannot influence history and that all humans are equal in this impotence — no one is inherently greater or more capable than anyone else. Napoleon refutes both — he is history, and his will controls the direction of events. But he is not a hereditary monarch; he is an upstart rising on his own merits. At once, he says to the monarchs, “Some men are destined to rule, but you are not those men. You don’t deserve your lot,” and says to the egalitarians, “You are not equal to me. None could accomplish what I have done”.
However, he also synthesized both positions. The egalitarians are right that monarchs are not predestined to rule — Napoleon shows that there are others with greater merit than the hereditary kings of Europe. He also validates the traditionalists that people are not equal — he is clearly more fit to rule than those who preceded him in the French Revolution.
This is what caused the crisis in literature and philosophy of the 19th century — whether you’re an egalitarian or a traditionalist, how do you explain the problem of Napoleon? And what does the fact that something like him occurred imply about the world?
Now, with all that background context out of the way, Stendhal tackles the problem of Napoleon from a sociological angle. He observes that Napoleon arose in a time of profound change, with France submerged in chaos due to the Revolution, and asks, “What happens when a Napoleonic figure arises in a society that is totally resistant to change?”
His answer is the character Julien Sorel, an extremely intelligent, Napoleon-obsessed youth from the lower class of the fictional town of Verrières, set during the Bourbon Restoration. Like his idol, Sorel possesses a formidable mind and intense ambition to rise from his lowly starting place in society. But unlike his idol, Sorel’s France does not reward competence and ambition. Instead, it places a premium on playing social roles and playing them well. As a result, Sorel’s ambition, which in an earlier age would have been channeled into great acts of heroism on the battlefield (or, in a future age, into founding a great company), was instead channeled into playing the roles that society valued in order to advance.
Thus, we see Sorel become a priest despite not believing in God, start affairs with various upper-class women without loving them, and tutor Latin despite not enjoying teaching Latin. He does these things because they are the legible paths by which a member of the lower class can aspire to move towards the upper class (but never fully join it).
Sorel is acutely aware of the incongruity between Napoleon’s life and his own — he frequently ruminates that his own quest for power, which involves lying and assuming social roles, is pathetic compared to Napoleon’s world-changing deeds. This incongruity forms the heart of the book and demonstrates the necessity of favorable cultural and societal circumstances for a Napoleonic figure to be fully actualized.
#8. Fyodor Dostoevsky, Notes from Underground
Dostoevsky remains a writer whose prose is fairly unenjoyable for me to read, but whose themes and ideas sit with me for long after I have completed the book. Notes from Underground will likely require several re-reads for me to fully absorb its points, but on my first pass, I came away with the following major takeaway: Dostoevsky strongly opposes the systematization of humanity.
In the first part of the book, the Underground Man spends much of his time asserting that the utilitarian ethic, namely, converting the good to a function that must be maximized, does not lead to fulfillment. And, even more strikingly, he says that elevating this conception of life to the highest good would necessitate the loss of free will. If we are optimizing a value function, there is a set of actions that maximize it. If we could wave a magic wand and have this set of actions revealed to us, then it would be congruous with our stated highest principle to follow these actions to the letter and incongruous to assert any form of free will. Hence, the highest form of “good” in the utilitarian perspective necessitates a loss of free will, a reduction of humans to automatons. The Underground Man states this and then also observes that, if you were to reveal this value function to people, they would act against it just to spite it and assert their free will. And if you forced humans to live this way and renounce their free will, it would be spiritual torture. Hence, the rational, utility-maximization approach is anti-human.
In the second part of the book, the Underground Man seems to espouse a philosophy that, on its surface, is diametrically opposed to utility maximization. Instead, he seems to be living his life through the most exaggerated form of performative Romanticism. He constantly makes irrational decisions based on fleeting passions that overtake him. However, he is very self-conscious about these actions — he does not act immediately upon feeling the emotion. Instead, he thinks that he should take action x in response to feeling y and ruminates on the fact that he didn’t take action x in the moment (sometimes for months at a time). It is only after berating himself that he then takes his “passionate” action in response to his emotions. In this way, the Underground Man is forcing himself to exist within a system that constrains his behavior — it is different and less legible than the utilitarian perspective he railed against in the first part of the book, but it nonetheless serves to constrain his freedom of will substantially, and leads to a similar spiritual sickness.
In both cases — through the Underground Man’s words in part 1 and through his actions in part 2 — we see the failures of forcing humanity into a behavioral box. As far as I can tell, Dostoevsky aimed to show that by constraining human behavior, we harm ourselves and become something like the Underground Man.
#9. Sally Smith Hughes, Genentech: The Beginnings of Biotech
A really fun history of the first major biotech company and the recombinant DNA technology that enabled it. It’s interesting to see the obstacles that Herb Boyer and Bob Swanson needed to overcome in order to make Genentech a reality — from raising capital from highly skeptical investors to convincing scientists that joining a company could be both scientifically meaningful and monetarily rewarding, the pair had to navigate so many issues that we now take for granted in startups. The contrast is stark with today’s AI boom, where investors will hand out billions to newly founded AI labs without the faintest hint of a business plan or even a differentiating idea.
Papers
For the papers I don't have much to say about beyond the contribution itself, I'll just give the challenge and the solution. That is, I’ll state the main challenge the paper addresses, followed by a brief description of the solution it proposes.
#1. Chai et al., MultiPath: Multiple Probabilistic Anchor Trajectory Hypotheses for Behavior Prediction (2019)
Challenge: Predicting future motion for agents in a scene is challenging because the set of potential outcomes is highly uncertain and multi-modal. Any approach that predicts only one future trajectory presents inherent problems. For example, how many times do we need to sample from this model to be confident that a pedestrian won’t jaywalk?
Solution: The paper introduces MultiPath, an approach that uses a fixed set of anchor trajectories (namely, the modes extracted from the dataset). The model then learns to output a probability distribution over these anchors, as well as an offset Gaussian that measures the deviation from the anchor (captured by the mean) and the position’s uncertainty (captured by the covariance). This setup allows us to model two kinds of uncertainty:
Intent uncertainty, captured by the distribution over anchor trajectories
Control uncertainty, captured by the probabilistic distribution over the agent’s state at each time step, conditioned on selecting a particular anchor.
#2. Nayakanti et al., Wayformer: Motion Forecasting via Simple & Efficient Attention Networks (2022)
Challenge: Self-driving cars receive inputs of many different modalities (velocities, positions, images, LiDAR, road graphs, traffic light states, etc.) and types (static vs. dynamic). Many solutions rely on combining results from modality-specific models, leading to highly complex and brittle systems.
Solution: Introduces Wayformer, a family of attention-based architectures for motion forecasting that are simple and homogeneous. Wayformer offers a compact model architecture comprising an attention-based scene encoder and a decoder. Ablations showed that early fusion of modalities in this architecture performed best. Achieved SOTA on Waymo Open Dataset.
#3. Gulino et al., Waymax: An Accelerated, Data-Driven Simulator for Large-Scale Autonomous Driving Research (2023)
Challenge: Simulation is crucial for generating larger training datasets and evaluating autonomous vehicle planning software. However, existing simulations are typically very expensive to run, may not reliably match real-world data when they generate scenes, and may not exhibit realistic agent behavior.
Solution: Waymax solves these problems with simulation by:
Improving speed through writing the simulator in JAX. This allows Waymax to be run on hardware accelerators (GPUs/TPUs)
Initializing simulations from real-world data in the Waymo Open Dataset. This grounds simulations in real trajectories.
Using agent models to control the dynamic objects in the scene.
#4. Jumper et al., Highly accurate protein structure prediction with AlphaFold (2021)
This was not my first time through this seminal paper (or the second or the third…), but it was the first time I went through it with the depth required to reimplement AlphaFold2 from scratch (note: still very much a work in progress!).
The AlphaFold2 paper itself is a relatively easy read, providing a brief overview of how the model works, how it fits within the frameworks of previous approaches, and the unprecedented performance it achieves. But it does leave a sizeable gap between a high-level understanding of what the model is doing and a true understanding of its inner workings.
For that, we need to dive into the 62-page supplementary paper (a full 5 times longer than the main paper!).
I think this piece is where the ingenuity of the AlphaFold team, as well as their clarity of insight, really shines. Each component of the model, labeled as an algorithm in the paper, is explained using a combination of text, diagrams, and complete pseudocode. In addition, the paper clearly outlines how each algorithm is stitched together in higher-level functions, such as the AlphaFold2 training loop or inference pass. And if that’s not enough, it even goes into great detail on the training setup & parameters, ablation studies to determine what parts of the network are truly necessary, and visualizations of the attention matrices to see what the model has truly “learned”.
To me, the clarity of the supplementary paper felt as if it were screaming out to me that it needed a code implementation that was just as clear. One that was not intended for production use or included dozens of Dockerfiles, deployment scripts, and ancillary supporting files, but instead emphasized clarity, pedagogy, and alignment with the paper's algorithm breakdown.
This, along with Andrej Karpathy’s minGPT, was the inspiration for my minAlphaFold2 project. The goal of this project is to align the model exactly with the supplementary paper’s structure and pseudocode, using only PyTorch primitives, with an emphasis on simplicity, clarity, and explanatory comments. Once the code portion of the project is complete, stay on the lookout for an “Annotated AlphaFold2”, in the same vein as Harvard’s Annotated Transformer project.
AlphaFold2 (along with GPT-3) represents one of the two largest breakthroughs in the history of artificial intelligence. And yet the pedagogical material available for AF2 is essentially non-existent when compared to the pedagogical material available for GPT-3-style models. I hope to do a small part in changing this.
#5. Zhu et al., Scaling Latent Reasoning via Looped Language Models (2025)
So my brief speculation tied to this paper caused quite a stir on ML Twitter:
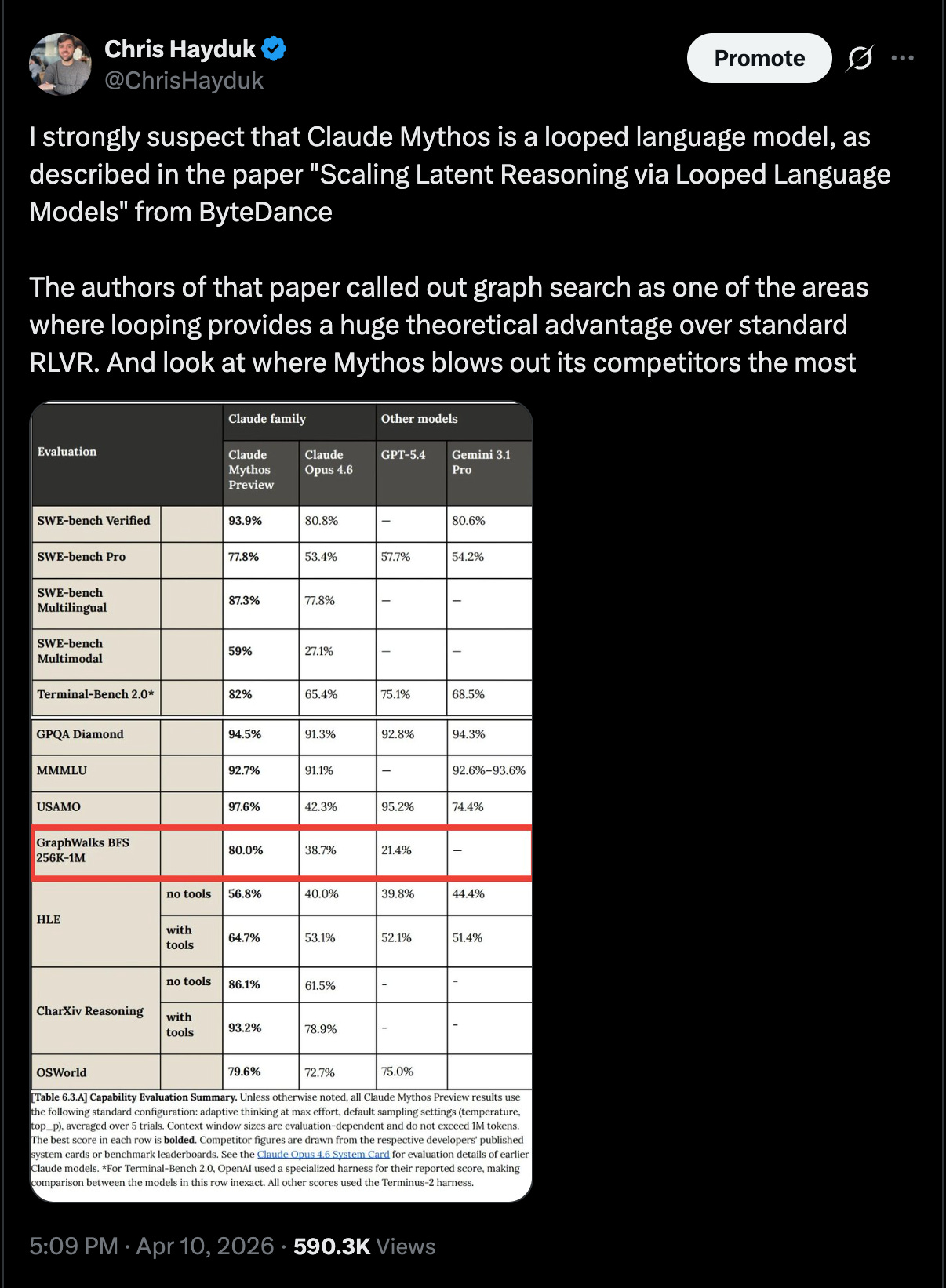
This was not meant to be taken as fact (or to blow up the way it did)! I was mostly just speculating based on the patterns I saw in the benchmark scores for Claude Mythos and some inferences on Anthropic’s compute budget. But here I’ll give a brief explanation of why it seems plausible to me that this architectural choice has made its way into the frontier models.
First, I’d like to point out (and thank you to Kalomaze on Twitter for setting this straight), that I don’t think the frontier models are using the main contribution from this paper (namely, the ability for the model to choose how many times it loops based on a prediction head that predicts the probability it has already arrived at the correct token). My claim is now a bit weaker — that the models may be trained using weight tying. That is, the model loops a deterministic number of times, feeding the last layer’s output embedding back into the input layer. This essentially increases the model's depth without increasing its total parameter count. As such, I would expect the training process to look more like recycling in AlphaFold2 (see supplementary paper linked above) rather than looping in the ByteDance paper.
Anyway, with that context out of the way, I’ll give a brief overview of why I think looping seems plausible for frontier models. First, we’ll start with the benchmark scores.
Since looping increases model depth without increasing parameter count, what you end up with is a decoupling of the model’s knowledge (i.e., what it has memorized) and the model’s reasoning (i.e., its ability to manipulate that knowledge).
To explain this phenomenon, I’ll include a screenshot from the ByteDance paper along with a brief explanation of this image from my piece The Unreasonable Effectiveness of LLMs in Mathematics:
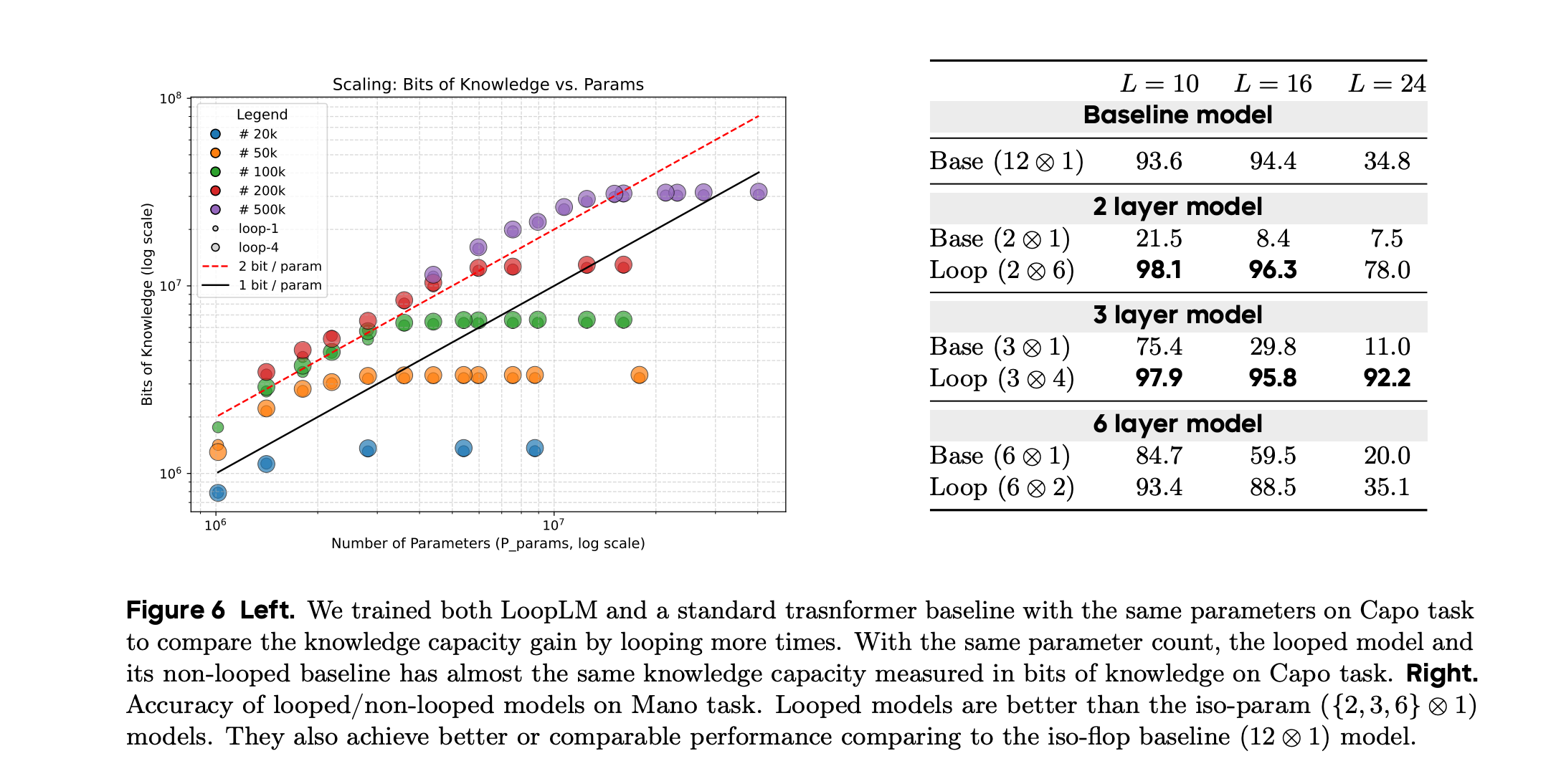
On the left-hand side of the image [above], the authors compared the bits of knowledge memorized by different train models (y-axis) to the number of parameters of those models (x-axis). For each model size, they trained a looped and a non-looped model variant, represented by large and small circles, respectively. You may not have noticed that there are two circle sizes on the graph because they basically overlap exactly for all model sizes. Thus, adding looping does not allow the model to learn more information.
Now, if we turn our attention to the right-hand side of the image [above], we can see the performance of a baseline transformer and a looped variant at different sizes on a reasoning-heavy benchmark. The numbers jump off the page — at each fixed model size, the looped model vastly outperforms the non-looped model. More astoundingly, a two-layer looped model substantially outperforms the largest non-looped model (the 12-layer variant in the first row).
I think we see this dynamic playing out in the benchmark results for Claude Mythos, captured in the Twitter screenshot I shared above. For benchmarks that rely more heavily on stored internal knowledge (e.g., GPQA and MMLU, which evaluate models on multiple-choice questions spanning a wide range of subjects), the improvement over Claude Opus 4.6 is fairly modest. We do see a larger improvement in Humanity’s Last Exam without tools, though these questions are designed to be more difficult than GPQA and MMLU, and as such, there is some level of gains that can be attributed to improved reasoning. (I also want to state here that, of course, Mythos is likely a larger model than Opus 4.6, so it will also have more knowledge memorized — the debate is on how much compute/capacity was devoted to reasoning vs. improved knowledge).
The benchmark that really jumped off the screen for me was GraphWalks BFS. This benchmark uses randomly generated sets of nodes and edges as input to the LLM. It then asks the LLM to perform various searches on this graph (e.g., find node X’s parent, start a breadth-first search from node Y and return a list of nodes you reach after 2 iterations, etc). These tasks, along with the fact that the nodes & edges don’t represent anything semantically meaningful, mean that this benchmark skews the most towards reasoning and away from memorized world knowledge out of any benchmark listed for Mythos. And, as we can see in the image, it is by far the biggest jump from Opus 4.6 to Mythos.
To me, this suggests that Mythos represents a relatively modest parameter scale-up and a much more aggressive depth scale-up, which would align with Mythos being a looped transformer.
Now for my second reason — compute constraints.
At this point, it’s no secret that the major labs are majorly compute-constrained. TSMC and NVIDIA have their capacities booked out years in advance, and the explosion in demand coming from coding models has only made this problem worse in recent months. As such, any innovation that can reduce the number of GPUs required to serve each batch of requests is of great importance to the labs — if a batch can be squeezed into fewer GPUs at equivalent levels of performance, the lab can serve more simultaneous batches and thus drive more revenue at a fixed level of compute.
Since a looped transformer results in more reasoning depth at a fixed parameter count, what you get is a smarter model that is able to fit in a smaller amount of GPU RAM. Exactly aligning with this critical constraint for the model providers.
Again, this is all speculation! I may be entirely off base! But these are the two major reasons that led me to strongly suspect that some form of looping is being used in Claude Mythos.
If you’ve made it this far, thank you for reading! This piece ended up being much longer than I had initially anticipated. As Joan Didion famously said, “I don't know what I think until I write it down”, and writing this article definitely revealed things I didn’t realize I had thought about these books and papers.
If there’s one thing I can leave you with, let it be this — please share what you’re reading!
Thank you for writing it! And the mention 😍
Hope you’ll share it on the Interintellect Discord too — people will love it 🥹